Создание кластера
На этой странице:
Настройка программного обеспечения
Выберите .
Нажмите Create Cluster.

Выберите режим Custom Config.
Далее укажите:
Cluster Name — название кластера.
Cluster Type — в Analysis cluster выберите все компоненты.
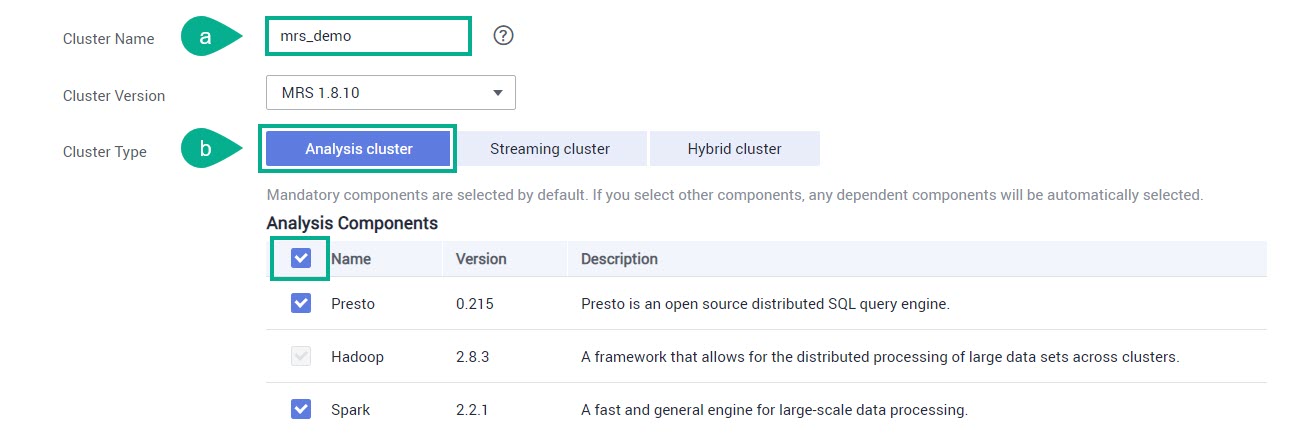
На странице ниже сделайте следующее и нажмите Next:
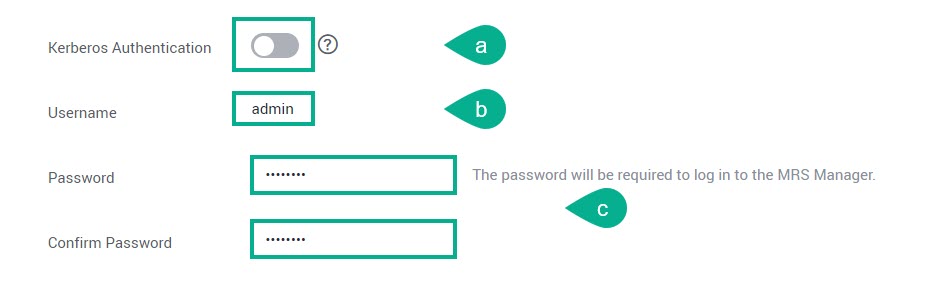
Kerberos Authentication — отключите проверку аутентификации Kerberos.
Username — по умолчанию имя пользователя «admin» для авторизации в MRS Manager.
Password и Confirm Password — укажите и подтвердите пароль для авторизации в MRS Manager.
Настройка средств аппаратного обеспечения
Заполните следующие поля:
AZ — выберите зону доступности.
VPC — выберите из списка сеть.
Subnet — выберите из списка подсеть.
На странице ниже заполните следующие поля и нажмите Next:
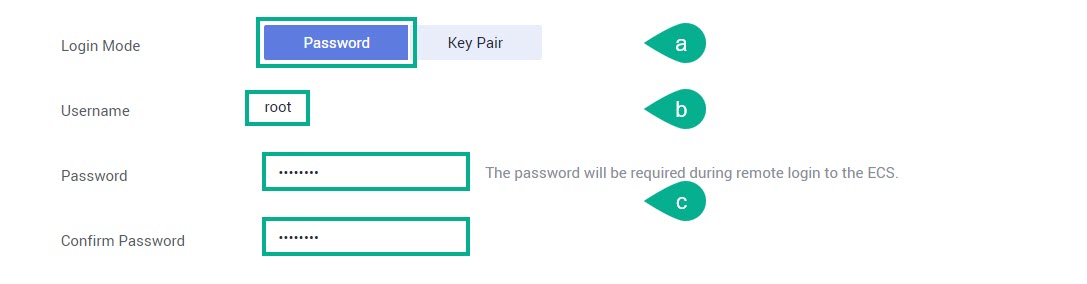
Login Mode — выберите режим Password.
Username — по умолчанию имя пользователя «root» для авторизации в узле ECS.
Password и Confirm Password — укажите и подтвердите пароль для авторизации в узле ECS.
В новом окне нажмите Create Now.
Нажмите Back to Cluster List.
Создание кластера займет некоторое время. Необходимо дождаться пока его статус не изменится на Running. Для обновления статуса кластера воспользуйтесь значком
 (Refresh).
(Refresh).
Подготовка программы и файлов с данными
На данном этапе будут использоваться тестовые примеры файлов с данными, а также программа Hadoop с установленным на нее компонентом wordcount.
Перейдите по ссылке для скачивания программы Hadoop с установленным компонентом
wordcount.Выберите, например,
hadoop-3.1.3.tar.gz. Распакуйте его. Программуhadoop-mapreduce-examples-3.1.3.jarвы найдете в каталогеhadoop-3.1.3\share\hadoop\mapreduce.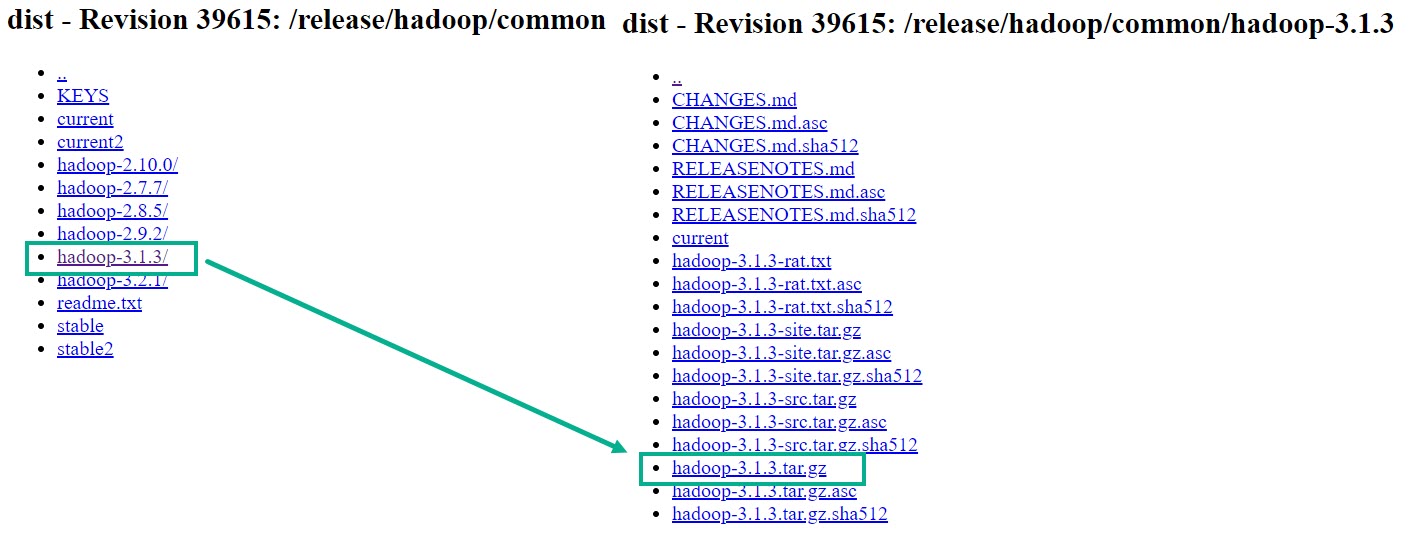
Подготовьте пару файлов формата
txt. В данном примере используем файлыwordcount1.txtиwordcount2.txt.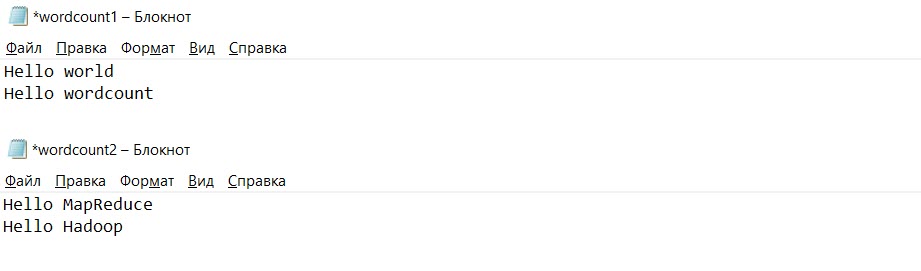
Выберите сервис .
Нажмите Create Bucket.
В поле Bucket Name укажите название бакета и нажмите Create.
Нажмите на название бакета.
Перейдите в раздел Objects и нажмите Create Folder.
В поле Folder Name введите «program» и нажмите ОК. После чего создайте еще одну папку с названием «input».
Перейдите в папку «program», нажмите Upload Object. Нажмите Add file и выберите скачанную ранее программу Hadoop, после чего нажмите Upload.
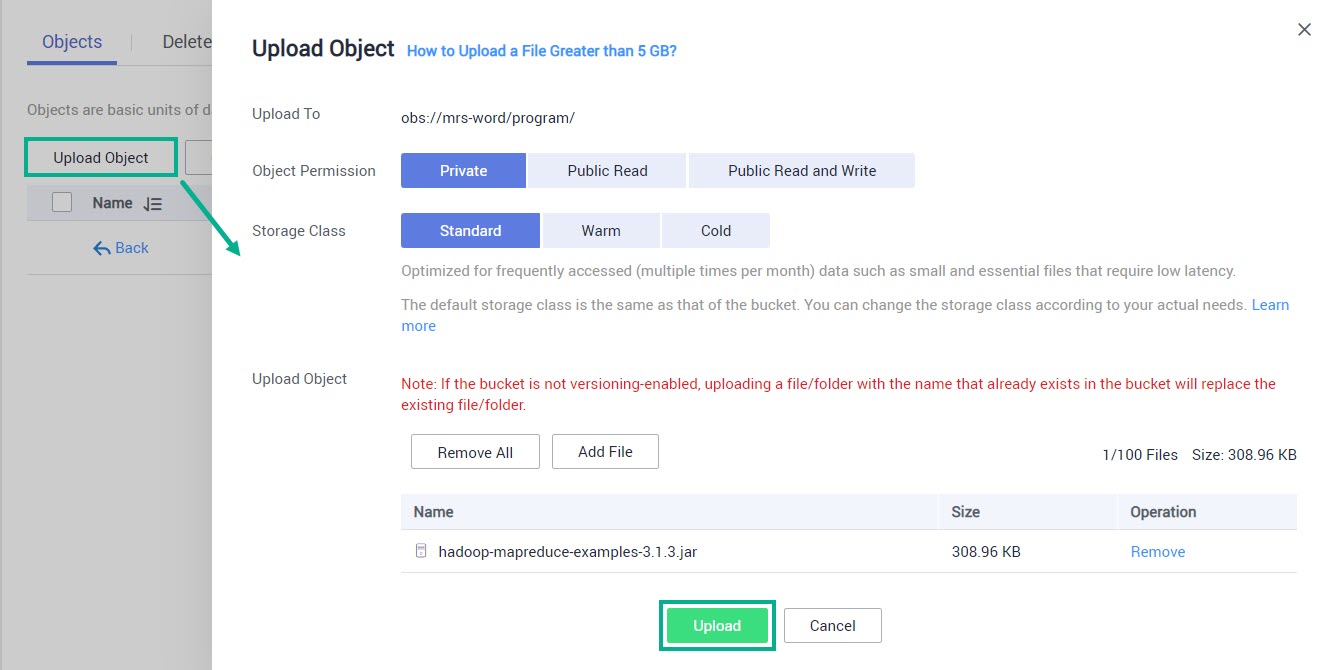
Перейдите в папку «input» и загрузите созданные ранее файлы
wordcount1.txtиwordcount2.txtпо аналогии с предыдущим пунктом.Теперь нужно создать и запустить задание (job).
для Dev & Test